I. Introduction - Much of the material covered in Molecular Genetics should be familiar to you from other courses. Thus the idea is to attempt to extend the basic knowledge that you already have with some additional details as indicated.
II. INSTRUCTIONAL OBJECTIVES
(1)Conceptual Objectives
- Understand the role of DNA in the transmission of genetic information.
- Describe DNA replication.
- Know what is meant by mutation.
- Summarize the Central Dogma or the flow of genetic information in organisms.
- Describe the essential elements of the genetic code.
- Understand the basic process of protein synthesis.
(2)Performance Objectives
- Describe the chemical composition of DNA.
- Understand the structure of the nucleotides.
- Recognize the major properties of the double helix, especially in the context of DNA replication or duplication.
- Understand the Meselson & Stahl (1957) proof of semiconservative replication of DNA.
- Describe the structural differences between DNA and RNA..
- List and understand the classes of RNA molecules.
- Describe transcription.
- Describe translation.
(3)Applications
- Describe how ultra violet (uv) light can be used to kill bacteria.
- Understand the way nucleoside analogues, like AZT, are used as antiviral agents.
- Recognize the potential for drug development using recombinant DNA.
- Understand the basis for DNA fingerprinting.
- Understand how antisense RNA molecules could be used as antiviral agents.
- Understand the basics of RNA viruses (retroviruses).
III. Material Overview
(1). Structure of the nucleotides - Nucleic acids, nucleosides, and nucleotides contain pyrimidine and purine bases (heterocyclic aromatic amines), a five carbon sugar, and phosphoric acid residues. The major pyrimidines are thymine, uracil, and cytosine, the major purines are adenine and guanine. Review the chemical structures of these heterocyclic aromatic amines, for example thymine is 2,4-dioxy-5-methyl pyrimidine.
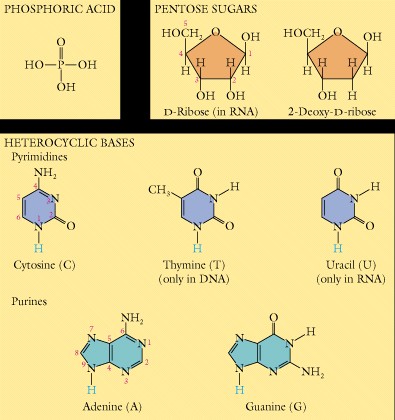
Nucleosides are beta-N-glycosides formed between a purine or pyrimidine and a sugar. The sugar is 2-deoxyribose in DNA and ribose in RNA. Nucleotides, the monomers from which the polymers DNA and RNA are made, are sugar phosphate esters of nucleosides. Thus deoxyribonucleotides are the monomers of DNA, and ribonucleotides are the monomers of RNA.
(2). Structure of DNA & RNA - DNA is a double-stranded polymer of 2'-deoxyribonucleotides linked by a 3' -> 5' phosphodiester bonds. The two strands run antiparallel to each other, i.e. one runs in a 3' -> 5' way and the other 5' -> 3' way, and are wound around each other to form a double helix. The sugar-phosphate backbone is on the outside of the helix, and complementary base pairs extend into the center of the helix. The base pairs are held together by hydrogen bonds.
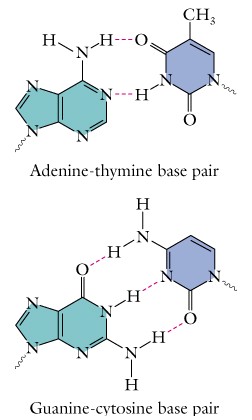
Adenine is always paired with thymine, and guanine is always paired with cytosine in DNA. RNA is usually single-stranded. The structure of DNA was proposed in 1953 by Watson and Crick based upon much evidence from a number of different laboratories, especially the X-ray diffraction evidence from Rosie Franklin and Maurice Wilkins which provided the important structural dimensions for the molecule.
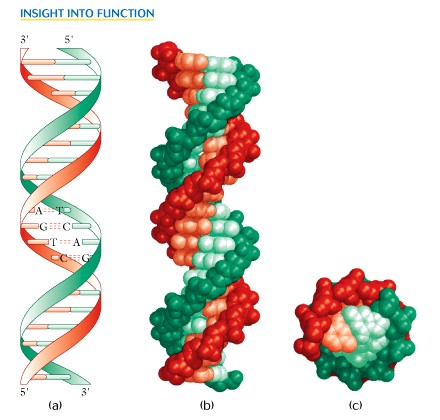
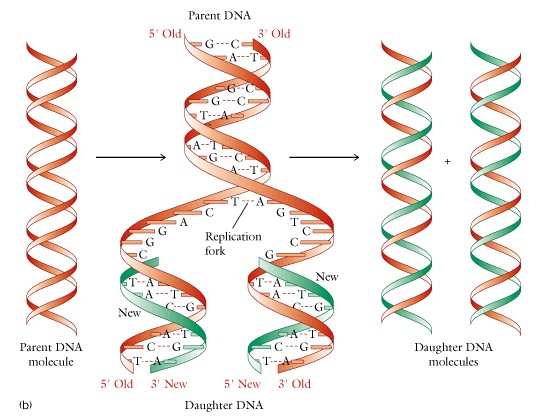
(3). DNA Replication - In DNA replication, each strand of the parent molecule serves as a template for the synthesis of a complementary daughter strand. DNA polymerase is the enzyme that catalyzes DNA replication. The process of replication is termed semiconservative, i.e. each daughter molecule consists of one parental strand and one newly synthesized strand. The key to the template replication is the specific pairing of the purine and pyrimidine bases via hydrogen bond formation. Please review this specific pairing and note the exact method of hydrogen bond formation by each pair of bases.
(4). The Flow of Biological Information. The Central Dogma of Molecular Biology states that the flow of biological information is DNA -> RNAs -> Protein. Transcription is the process by which the genetic information in DNA is copied to produce several types of RNA molecules. One of the major types of RNA is messenger RNA (mRNA), which carries the code for a protein. Other types are ribosomal RNA (rRNA) and transfer RNA (tRNA) and they function in protein synthesis. The enzyme for RNA synthesis is RNA polymerase and this enzyme unites the individual nucleotides into the RNA product. Transcription occurs in three stages, initiation, elongation, and termination. Eukaryotic genes contain introns, which are sequences that do not code for an amino acids, and are removed from the transcript by a process of splicing. The final mRNA molecule contains only the protein coding sequences or exons. Genes are also divided into structural and regulatory types. Structural genes encode proteins, whereas regulatory ones carry out various regulatory functions.
5. The Genetic Code. The logic for the genetic code asks what
is the relationship between the four letter alphabet of DNA (A,T,G,C),
the four letter alphabet of RNA (A,U,G,C), and the twenty letter alphabet
of proteins (amino acids). The clear answer is that at least any three
letters of the bases provides enough combinations to code for the twenty
amino acids, i.e. with three letters, a triplet code, some 64 different
possibilities occur. How many combinations would a duplex, any two letters,
code provide? Note that including several codons for start and stop, each
amino acid is encoded by more than one triplet. This condition is called
degenerate, since each amino acid has several codons rather than just
one. The sequence of triplets in mRNA should be colinear with the sequence
of amino acids in the resulting protein. Examine the table of mRNA codons
for the amino acids in the textbook.
6. Protein Synthesis. Translation, the process of protein synthesis,
occurs in the cytoplasm on organelles called ribosomes (actually polyribosomes),
which are complexes of RNA and structural protein that bind the mRNA molecules
and provide a site where translation occurs. During translation the sequence
of nucleotides in mRNA, read as triplets, is translated into a sequence
of amino acids in the protein. An important player in this process is
tRNA, which can be termed the coupling factor, since it binds one of the
20 amino acids and then reads the proper triplet on the mRNA molecule
for this particular amino acid. It holds the amino acid in the right place
so that the enzyme can now form the peptide bond to link this amino acid
to the growing polypeptide chain. Thus there are 20 specific tRNA molecules,
one for each of the amino acids. The reading of the proper triplet on
the mRNA molecule occurs via the same method as base pairing in the DNA
molecule, that is by hydrogen bonding between compatible bases. The process
of protein synthesis is very complex and requires many enzymes and energy.
7. Mutation. Any change in a DNA sequence is considered a mutation,
and mutations are classified as several different types according to the
type of change. For example, there are base substitutions, base insertions,
or base deletions, and all are considered to be point mutations. Because
of the degenerate nature of the genetic code, some changes in the DNA
would result in no change in the amino acid sequence. A number of environmental
factors can cause mutations, including ultraviolet light and a number
of chemicals.
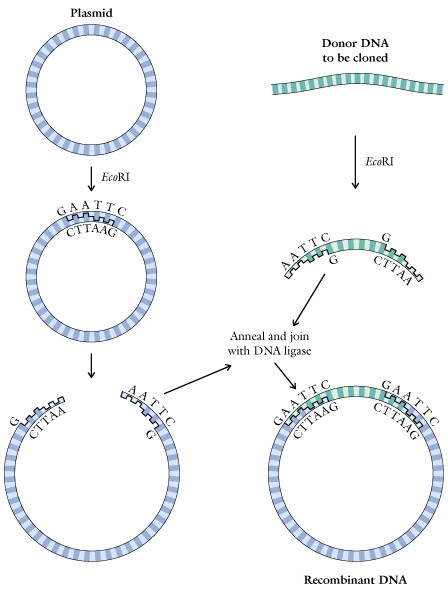
8. Genetic Engineering and Recombinant DNA. Review restriction enzymes, a unique class of some 200 different endonucleases formed by bacteria to restrict the entry of foreign DNA molecules into bacterial cells, cloning vectors, plasmids, transformation, and other aspects of recombinant DNA. Recall retroviruses or RNA viruses and their unique enzyme reverse transcriptase, which is an exception to the Central Dogma. The human genome is in the process of being sequenced, and is considered to contain some 3 billion bases.