
I. Introduction - The twenty naturally occurring amino acids form the alphabet of proteins. This alphabet allows a very large number of different proteins including: enzymes, hormones, the lens protein of the eye, feathers, spider webs, tortoise shell, milk proteins, enkephalins, antibodies, mushroom poisons, etc. When proteins are boiled with strong acid or base, their covalent linkages are broken and the amino acids are released. These free amino acids are relatively small molecules and their chemical structures are known. The first amino acid to be purified and characterized was asparagine in 1806 and the 20th was threonine in 1938. Most of the names of the amino acids are trivial and were often derived from the original source of isolation, i.e. asparagine from asparagus, glutamic acid from wheat gluten, etc.
Understanding the structure of the amino acids is essential to understanding the much more complex structure of proteins.
II. Amino Acids - A good place to begin the understanding of the amino acids is to consider their structure/function relationships. Some of these relationships are:
(1) All have at least one free carboxylic acid functional group.
(2) All, except proline, have at least one free amino functional group.
(3) All with a single amino group and a single carboxyl group form a dipole in solution at pH 7.4. All of these is also an acid or proton donor and a base or a proton acceptor. Thus at pH 7.4 the carboxyl group, behaving as an acid has lost the proton from the hydroxyl group and carries a negative charge, and the amino group, behaving as a base has accepted this proton and carries a positive charge.
The titration curve has two distinct points and values: the carboxyl pK is about 2.34 and the amino group value is about 9.69. (Note as a point of reference that the value of 2.34 is about 100X more strongly dissociated than the carboxyl of acetic acid value of 4.76, this results from the electrostatic repulsion of the carboxyl proton by the positively charged amino group.)
Finally, each R-group may also have a unique dissociation constant, for example histidine with a value of 6.0 is the only one with a potential for buffering cellular contents at about 7.0.
We will later note that hemoglobin is rich in residues of histidine, and thus has a cellular function in buffering red blood cells. This type of information also has practical importance, since different amino acids can be separated on the basis of direction and relative rate of migration when they are placed in an electric field at a known pH. These two types of separation techniques are termed electrophoresis and ion-exchange chromatography.
(4) All except glycine, where R=H, have at least one chiral carbon. Naturally occurring ones are of the L-form configuration. In addition, as we will see later the peptide bond which covalently links together the amino acid residues is not free to rotate and behaves like a double bond providing the cis/trans configuration. The configuration found in native proteins is always the trans-form.
(5). Hydrogen bonding is possible because of the carboxyl and amino functional groups. Recall the formation of a hydrogen bond and the role that electronegativity plays in this formation. In addition, the R-group may also provide for additional hydrogen bonding.
(6) The presence of a thiol functional group, an example is cysteine, allows for covalent bonding via the (-S-S-) disulphide linkage. Recall that the oxidation of two thiol groups produces this linkage. Such linkages are important in folding a polypeptide chain or covalently linking together polypeptide chains.
(7) The R-group is important in hydrophilic and hydrophobic interactions. The most important non-covalent method for producing the unique shapes of proteins is hydrophobic interactions.


(8) In the human diet, the so-called dietary protein must include the 8 amino acids isoleucine, leucine, lysine, methionine, phenylalanine, threonine, tryptophan, and valine, since we do not have the genetic information for their biosynthesis. The label "complete dietary protein" is used to indicate that a protein contains all of these amino acids.
A major research effort utilizing genetic engineering has been made to increase the content of these amino acids in various plant products, including the important grains, in order to better supply them in the human diet.
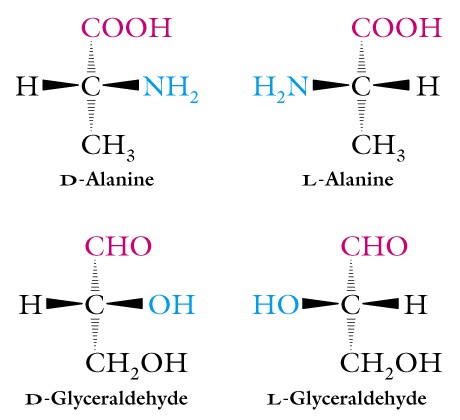
III. Optical Activity and Stereochemistry of Amino Acids - Except for glycine, all of the amino acids isolated from proteins have four different groups attached to the alpha-carbon atom. Thus this carbon atom is said to be chiral or asymmetric and the two possible configurations for the alpha-carbon constitute nonsuperimposable mirror image isomers, or enantiomers. Such molecules display a special property called optical activity, the ability to rotate the plane of polarization of plane-polarized light.
Two systems of nomenclature for chiral molecules are in use today. They are the D, L system first proposed in 1906 by M. A. Rosanoff (the one we are using) and the R, S system.
In the D, L system the isomers of glyceraldehyde are the standard for all other molecules and this system does not consider the specific optical activity. Recall that you have learned these two structures. Thus D- and L-forms of amino acids follow this pattern, and the amino group rather than the hydroxyl is written to the right or left to indicate the two forms.
The R, S system was introduced in 1956, to help overcome the problem for molecules with two or more chiral centers. In this system, priorities are assigned to each of the groups attached to a chiral center on the basis of atomic number, atoms with higher atomic numbers having higher priorities. There are several amino acids, including isoleucine, threonine, hydroxyproline, and hydroxylysine, which have two chiral centers and this system is better than the D, L one for such molecules. We want to be aware of the R, S system, but will not use it.
IV. Peptides or Polypeptides - the peptide bond is formed by removing a hydroxyl from the carboxyl of one amino acid and a hydrogen atom from the amino group of a second amino acid to form water, via a process termed dehydration synthesis. Note that the resulting dipeptide contains a free carboxyl and a free amino group and thus any number of additional amino acids can be added forming the polypeptide.
The naming begins from the amino-terminal and proceeds to the carboxyl
terminal, and the sequence of amino acids is called the primary structure
of a protein. For a molecular weight of 34,000 or 34K containing 12 different
amino acids in equal numbers there are over 10300 different
sequences possible. Note that the peptide linkage i.e. an amide
formed between the carboxyl and the amino groups, occurs in the trans-configuration.
Thus the carbonyl oxygen is trans-across the peptide bond to the hydrogen
of the amino group. Form a dipeptide from two amino acids and be sure
that you can see this configuration.
V. Classification of Proteins - proteins are classified according to their shape. They may be:
- FIBROUS as long, stringy forms along one axis and insoluble in water;
- GLOBULAR as a chain or chains folded into a compact spherical or globular shape, usually soluble in water and having a dynamic function such as enzymes;
- or CONJUGATED and containing a non-protein part termed the prosthetic group, consisting of lipid, carbohydrate or metal ions.
Proteins tend to be very large molecules with molecular weights of 5K
to 1000K, and the number of amino acids can be estimated by dividing the
MW by 110 (the average molecular weight of the 20 amino acids is 138,
and since the small ones predominate in most proteins, this number becomes
128, and with the formation of the peptide bond a water molecule is formed,
subtract 18).
A good example of a protein is insulin, which was the first protein
to be sequenced by W. Sanger, and is well known for its regulatory role
in sugar metabolism. The functional protein consists of two polypeptide
chains: the A chain has 21 amino acids including 4 cysteine residues;
and the B chain has 30 amino acids including 2 cysteine residues. The
A chain is identical in human, pig, dog, rabbit, and sperm whale, and
the B chain is identical in cow, pig, dog, goat, and horse. The changes
which occur among the various forms do not alter the function of the molecule.
The cysteine residues are important in forming the final globular shape
of the molecule, in chain A the first one occurs at position number 6
and this forms a covalent linkage with number 11 in chain A producing
a loop in the chain. The next cysteine residue in chain A occurs at position
7 and this residue forms a covalent bond with the same residue at position
7 in chain B, finally a residue at position 20 in chain A cross-links
with the same residue at position 19 in chain B. These (-S-S-) linkages
are important in producing the final functional shape of the molecule.
Some insight into how these linkages and other interactions shape the
functional molecule is given by the fact that the beta-cells of the pancreas
produce a pro-insulin protein of 84 amino acids, which is then processed
to remove 33 amino acids leaving the 51 total residues indicated above.
VI. Fibrous proteins - These proteins have simpler structures than the globular ones and their 3-D structure has been determined by x-ray analysis. They constitute 1/3 of typical body protein in vertebrates and provide external protection as components of skin, hair, feathers, nails, and horns. They also provide support, shape, and form as components of connective tissues including tendons, cartilage, bone and the deeper layers of skin.
One example is the alpha-keratins found in hair, wool, feathers, nails, claws, quills, scales, horns, hooves, tortoise shell, etc. They are made within epidermal cells of skin, first as filaments, then as rope-like or cable-like structures which fill the cell as it flattens and dies. X-ray analysis in the 1930's gave a characteristic diffraction pattern indicating a repeating unit of about 0.54 nm along the long axis. Silk fibers, a beta-keratin gave a value of 0.70 nm, and if hair was steamed it gave the same value.
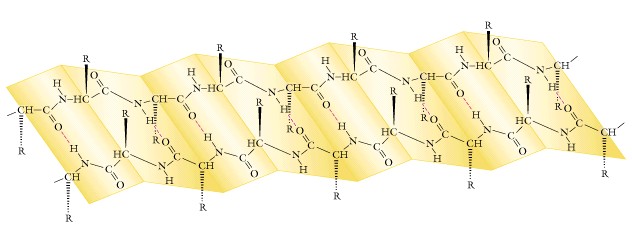
In the 1940-50's Linus Pauling (whose fame we have noted previously) along with his student Robert Corey made x-ray diffraction patterns of crystals of amino acids and di- or tri-peptides and proposed a structure for the peptide bond. The results suggested that the carbon to nitrogen bond was shorter than expected and had some double-bond characteristics like the inability to freely rotate, and the 4 atoms of the amide linkage group were in a single plane, such that the oxygen of the carbonyl and the hydrogen of the amino group were in a trans-configuration. They concluded that the back-bone of the peptide chain was a series of rigid planes which imposed constraints upon the number of conformations, and termed this linkage the planar peptide group. Other single bonds in the backbone may also interfere with this structure depending on their size and charge in the various amino acid R-groups. Pauling and Corey then studied the polypeptide chain and found that the simplest arrangement was an alpha-helix ( a helix circumscribes a cylinder and is of uniform diameter from top to bottom). The repeating unit of 0.54nm is a single turn of the helix and the R-groups protrude outward from the helical backbone. The forces holding the alpha-helix are hydrogen bonds between EVERY hydrogen atom attached to the electronegative nitrogen atom of the peptide linkage and the electronegative carbonyl oxygen atom of the FOURTH amino acid residue behind it in the helix. EVERY peptide bond of the polypeptide participates in the hydrogen bonding. This alpha-helix is a stable conformation because of two types of constraints to free rotation around single bonds:
(1) the non-rotating planar peptide bond; and
(2) the formation of many intra-chain hydrogen bonds.

Examine the structure of the 20 amino acids and determine which ones
are NOT compatible with the alpha-helix!!
The alpha-keratins are rich in cysteine. Hair or wool consists
of three strands of the alpha-helix held together by (-S-S-) bonds producing
a super-coiled protofibril and these produce bundles of microfibrils,
and finally macrofibrils or hair. The hardest and toughest alpha-keratins
are tortoise shell protein and contain 18% of cysteine residues and a
high number of cross-links. Alpha-keratins are insoluble because of the
presence of hydrophobic amino acids, such as phenylalanine, exposed on
the outside of the fibrils. When globular proteins contain hydrophobic
amino acids they are hidden inside the molecule and only hydrophilic residues
are found on the surface providing the soluble character.
The beta-keratins such as fibroin found in silk and spider webs has a 0.70 nm repeating pattern, the same value found in steamed alpha-forms where the hydrogen bonds have been broken. The more extended conformation of fibroin resembles a PLEATED SHEET with no INTRA-CHAIN hydrogen bonds. Instead there are INTER-CHAIN hydrogen bonds between the peptide linkages of adjacent polypeptide chains. The R-groups protrude out from the zigzag structure and adjacent chains are usually antiparallel rather than parallel as seen in the alpha-forms. Generally no cysteine cross-links are present, and the R-groups of the amino acids are small. In silk about 50% of the residues are glycine.
Think about "permanent waving of your hair" as a biochemical process, remembering that many cysteine residues and cross-links are present. Collagen makes up about 1/3 of the body mass in humans and is a major fibrous protein. It makes up the cornea of the eye, and leather is almost pure collagen.
Boiling collagen in water produces gelatin, and this hydrolysis of some covalent bonds is the main reason for cooking meat, since it is collagen and blood vessels that make it tough. Collagen is about 35% glycine, 11% alanine, and a high content of proline and hydroxyproline, thus is known as a poor dietary protein. Myosin and actin are two other proteins of great interest.
Review the text for these two proteins.
VII. Levels of Protein Structure - Fibrous proteins tell us much about the structure of proteins and we have seen that proteins possess not only a
PRIMARY STRUCTURE consisting of the amino acid sequence held together by the covalent bonding of the peptide linkages, but also a:
SECONDARY STRUCTURE arranged in space. This secondary structure is spontaneous and results from the amino acid content and sequence i.e. the primary structure. It consists of an alpha-helix produced from intra-chain hydrogen bonding, or a beta-pleated sheet produced from inter-chain hydrogen bonding. There often follows a 3-D structure or conformation that serves a specific biological function. The globular proteins demonstrate two additional levels of protein structure and will now be mentioned.
TERTIARY STRUCTURE is determined by longer-ranged aspects of the amino acid sequence, especially the nature of the R-groups.
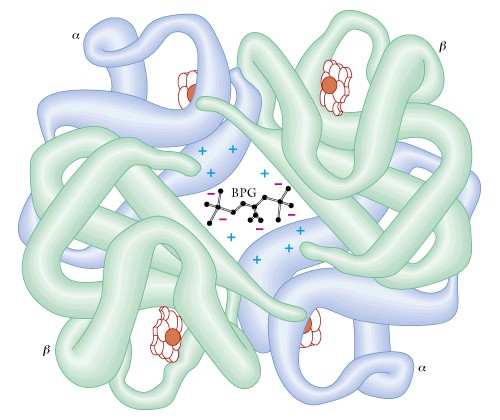
Finally, QUATERNARY STRUCTURE is found in those proteins that contain more than one polypeptide chain. We covered the example of insulin previously, another example is hemoglobin which contains two alpha chains plus two beta chains as well as the heme pigment molecules. An extreme example is the enzyme pyruvate dehydrogenase, a key enzyme in energy metabolism, which contains 72 chains.
VIII. Globular proteins - are those forms which are folded into a compact, globular shape, and are usually soluble in water. The enzymes are good examples of globular proteins. The folding into a compact shape is illustrated by serum albumin, which has a molecular weight 64,500, and consists of one polypeptide of 584 amino acids folded into a spherical molecule of 13 x 3 nm. If it was an alpha-helical rod in shape it would be about 90 x 1.1 nm, or if it had a beta-conformation it would be about 200 x 0.5 nm. This type of folding is called TERTIARY STRUCTURE and we will cover in lecture the case of myoglobin as an example.
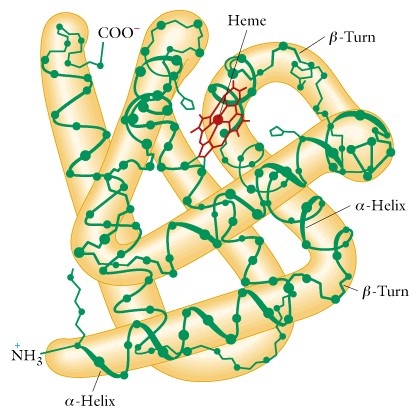
In general, there are about four major forces that stabilize the tertiary structure in many globular proteins. These are:
- hydrogen bonding between the R-groups of residues in adjacent loops of a chain;
- ionic attractions between oppositely charged R-groups;
- hydrophobic interactions between R-groups which places such groups in the interior of the molecule;
- and covalent cross-linking including sulfur-to-sulfur ones using cysteine residues.
It is generally accepted that hydrophobic interactions are a major force
in the production of tertiary structure.
IX. What determines the primary structure of a protein? Answer: The sequence of the amino acid residues.
What determines the sequence of the amino acid residues? Answer: the base sequence in mRNA.
What determines the base sequence in mRNA? Answer: the base pair sequence in DNA. Thus the flow of genetic information begins with the gene and ends with a protein, whose unique structure allows it to carry out a specific function(s).