|
Project Links
Seth's Homepage
Speech ID Main
Program Download
|
|
The goal of this project was to combine whatever code could
be found, and write what couldn’t to create a speaker verification program
that ran on the average Windows computer using the soundcard for input. Because
of these goals, the project was written in C++ with the Visual C++ compiler.
The author was able to write a program that would train and test data. The
results from comparing the probability of the test data and the training
data from the model would ideally show how likely the test data was from
the same person as the training data. This system seemed to work best with
background noise.
|
Speaker Verification vs. Speaker
ID
|
This project is speaker verification. Speaker verification asks the
question, “Is this person really who they say they are?” The flow of events
runs like this, the person tells the computer who they are, the computer
asks for a password, the person says the password, and the computer tells
them if they passed the test.
Speaker ID asks, “Who of the people I know is this most likely to be?” In
this case, the computer has a database of models for different people. When
the test case comes in, the computer compares it to all the models, and chooses
the most likely one. This is very similar to speaker dependant speech recognition,
only the computer is distinguishing between people instead of words.
This project is speaker ID, because the author (me) would like to have his
computer identify the people coming into his apartment. The goal is to have
the computer also be the answering machine. That way, when I walk in the
door, it asks me who I am, and then tells me if I have any messages and who
left them.
The main two sets of features used in speaker verification (ID is the same)
are Mel-Cepstrum (MFCC), and delta Cepstrum (DFCC). The Glottal flow derivative
(GFD) also works well for speaker verification, but the author has studied
MFCC much more and MFCCs are easier to derive, so that is what he used. The
C++ functions he found could calculate the MFCC, DFCC (which is the first
derivative of the MFCCs), and the second derivatives of the MFCCs.
|
Gaussian Mixture Modeling
|
Gaussian mixture modeling can be thought of as using multiple Gaussians to
fit a non-Gaussian data set. This is not a temporal modeling scheme, unlike
the Hidden Markov Models. The parameters have to be found iteratively, usually
through an expectation maximization process.
Here is a list of the software examples I looked at:
Jialong He
's library
CSLU Toolkit
X. H. Li
's
HTK Speech Kit
Microsoft
Speech API
E-Med Innovations Inc.
Article with code
Paul Cheffers
Multithreaded wave interface
The two sets of software I found that I could coerce into doing what I wanted
were X. H. Li’s and E-Med Innovations from
Codeproject
.
I did some rework in the E-Med Innovations software to make the recording
energy sensitive. The goal was to cut out most of the silence in the recording.
Then I added a method to X. H. Li’s CGMM class to test data against the GMM.
Then I wrote the software to connect everything together. This means I spent
most of my time trying to figure out how other people’s software worked.
Once I had it figured out, I had to figure out how to get the data I needed
out of it. This became a problem in some of the packages I tried. Some were
pretty easy to use, but I needed to extract the wave data and plug it into
my feature calculation classes. Unfortunately, some programs wouldn’t allow
this. Then, I figured out how to get the data out, but it was a void* to
shorts and I needed a float*. So Seth learned a bit more C++. Finally, everything
was just getting going, and the earlier stuff began to break down. So I looked
everything over carefully, found where the problems were, and now it runs.
Here is an example of what the GUI looks like:
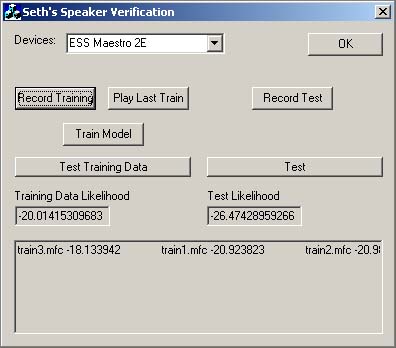
First, pick the device to use for sound. Second, click Record Training to
record a training sample. After you stop recording it will tell you it successfully
recorded it, and then extract the features. This program only uses MFCCs
right now. All data is stored in a data subdirectory from the working directory
of the program. You can play the last training data to see what it sounds
like (sorry can’t erase it from in here yet). Once you have a suitable number
of training samples, click Train Model to train a GMM. The GMM is trained
from all the train*.mfc files in the params.lis file. You can edit this to
change which ones to use. The Test Training Data button shows the average
likelihood of all the training samples. It also shows the individual likelihoods
in the window below. Now that there is a model, click on Record Test to record
a test sample, then Test to see what the probability of the test sample is.
The likelihoods are the sum of all the likelihoods for the each 100
ms window of speech from the model. Because these are log-likelihoods they
are negative and the more negative numbers are less likely. I tested it with
myself as both the test and training, and the results were inconclusive.
However, if you train it and then test it on silence (background noise) the
likelihood is very good. It makes me a little suspicious. Comparing it with
other speakers, the differentiation is not great. Right now it is running
on 10 MFCCs, and a 5th order GMM. I trained it with 10 training samples of
~1 second each.
It may have been more worthwhile and faster just to write all the functions
myself from scratch, particularly the feature extraction and model functions.
The wave I/O would have been a bit more challenging. But I did succeed in
getting everyone’s functions working together pretty happily. I was surprised
at two things: how few functions are on the web to do exactly what I wanted,
and how difficult it is to use someone else’s code to accomplish what I wanted.
If I did it again, I would probably have done a Matlab project because I
know it better and it gives results in a much better presentation.
More testing to determine exactly what is going on is needed. This was curtailed
to get the project turned in. Next, I would add a multimodel system to do
speaker ID, and make the recording system better by checking the energy level
and automatically cutting off when there has been silence for sometime. Also,
I would make it automatically detect the background noise level and possibly
model it to subtract it out. I was reading in [2] and they say that even
recording in the same location with the same people a couple of days apart
can give different results.
|
Works that inspired this project
|
All the webpages told a little more about what could be done, and what was
being done.
[1] Quatieri, T. Discrete-Time Speech Signal Processing. Prentice Hall, NJ.
2002
[2] Strom, P, et al. Speaker Recognition for User Identification and Verification.
Project Course in Signal Processing and Digital Communication at the Royal
Institute of Technology, Sweden. 2001.
|